How modern AI actually works, in seven ideas
A plain-language tour of how LLMs really work: next-word prediction, training and the frozen model, words as vectors, attention, the transformer, RAG, and agents. With screenshots from the interactive course See How AI Works.
Modern AI can feel like a black box, but the core ideas are more graspable than they look. I spent the last few months building an interactive course, See How AI Works, that explains them one at a time, each with something you operate yourself instead of a wall of text.
Here are seven of those ideas. Together they cover most of what happens when you type a question into ChatGPT or Claude, and each one is a lesson you can try for free.
1. An AI only predicts the next word
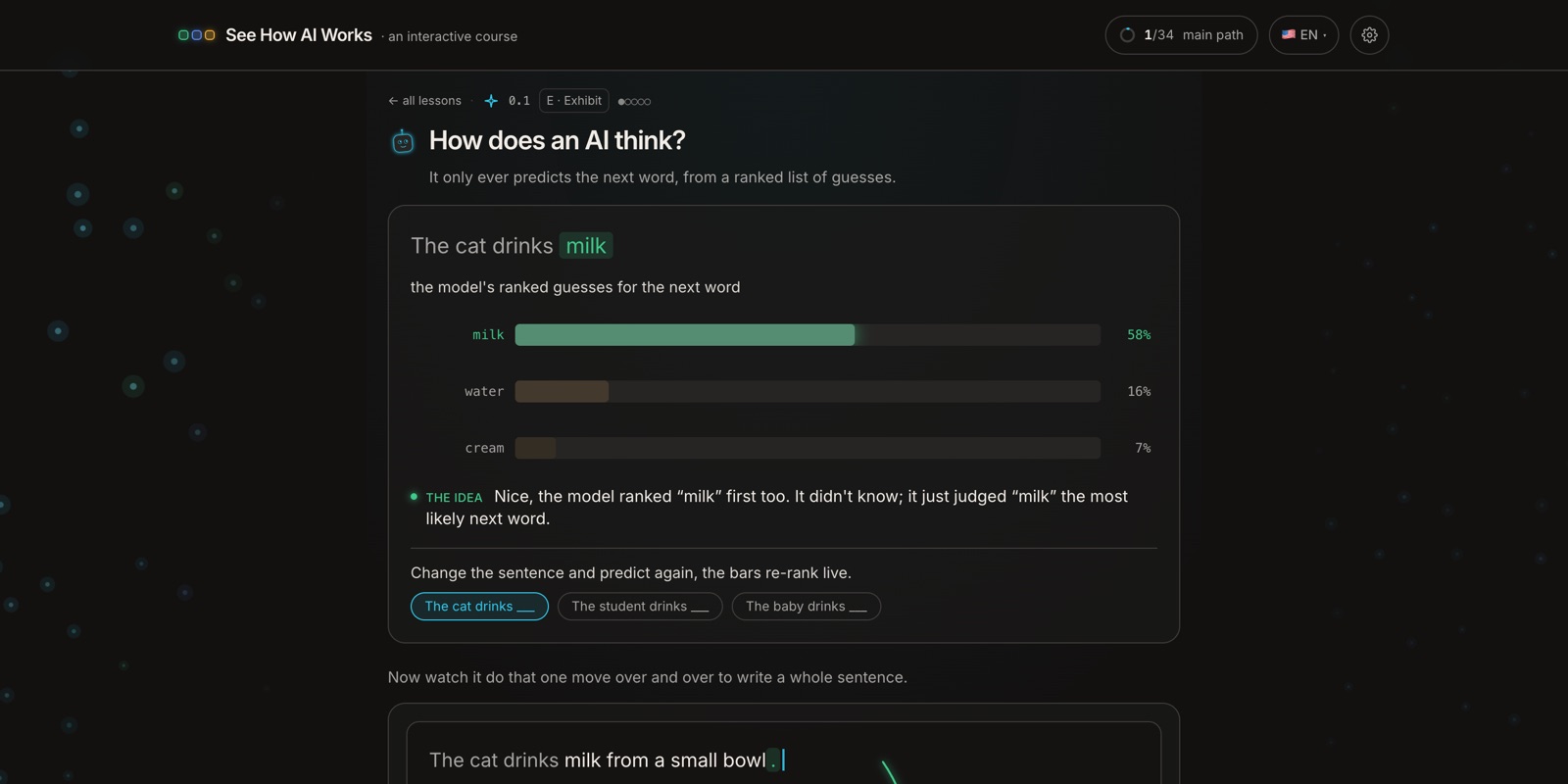
At its core, a language model does exactly one thing: it reads the text so far and predicts the next word. Then it adds that word to the text and predicts again. There's no lookup and no stored answer, just a ranked list of likely next words and a pick near the top.
The course opens by letting you be the model. You give it half a sentence, and it shows its ranked guesses with probabilities: milk at 58%, water at 16%, cream at 7%. It didn't "know" the answer; it scored every candidate and took the most likely one. Repeat that single move a few hundred times and you get a whole paragraph. Everything else below is really just about making that one guess sharper.
2. Its knowledge is trained in, then frozen
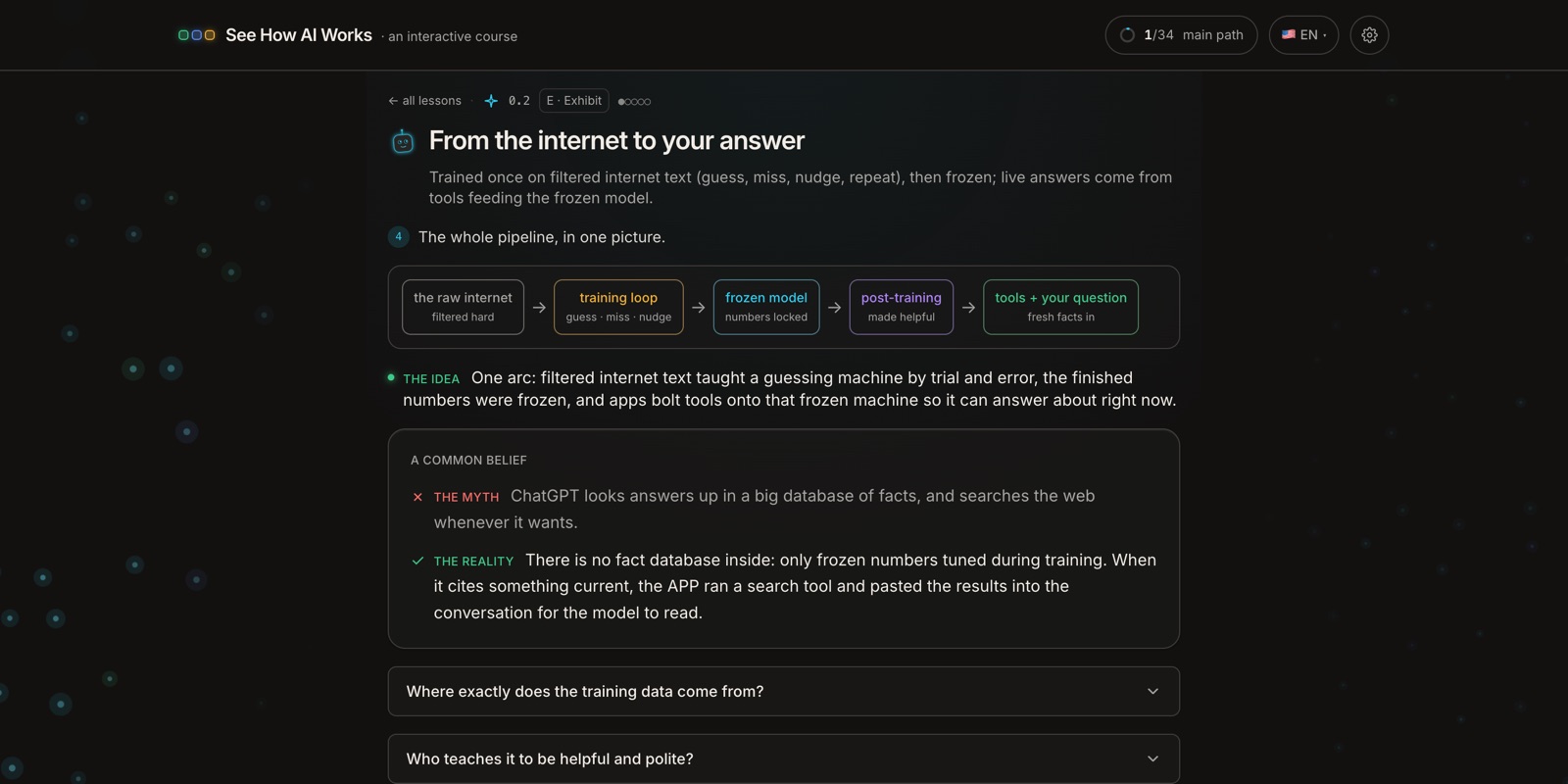
So where do those rankings come from? The model is trained once, by playing that guess-the-next-word game across a huge, filtered chunk of the internet and nudging itself every time it guesses wrong. When training ends, the numbers are frozen.
That's the reason every model has a knowledge cutoff and can't natively know today's weather or news. When a chatbot does answer about right now, the app around it ran a tool (a search or a lookup) and pasted the result into the prompt for the model to read. It never "went online".
The lesson draws the whole thing as one picture (raw internet → training loop → frozen model → tools) and clears up a common myth on the way: there is no fact database inside the model, only frozen numbers. Anything current got there as text someone handed it.
3. Words become numbers, and closeness means similarity
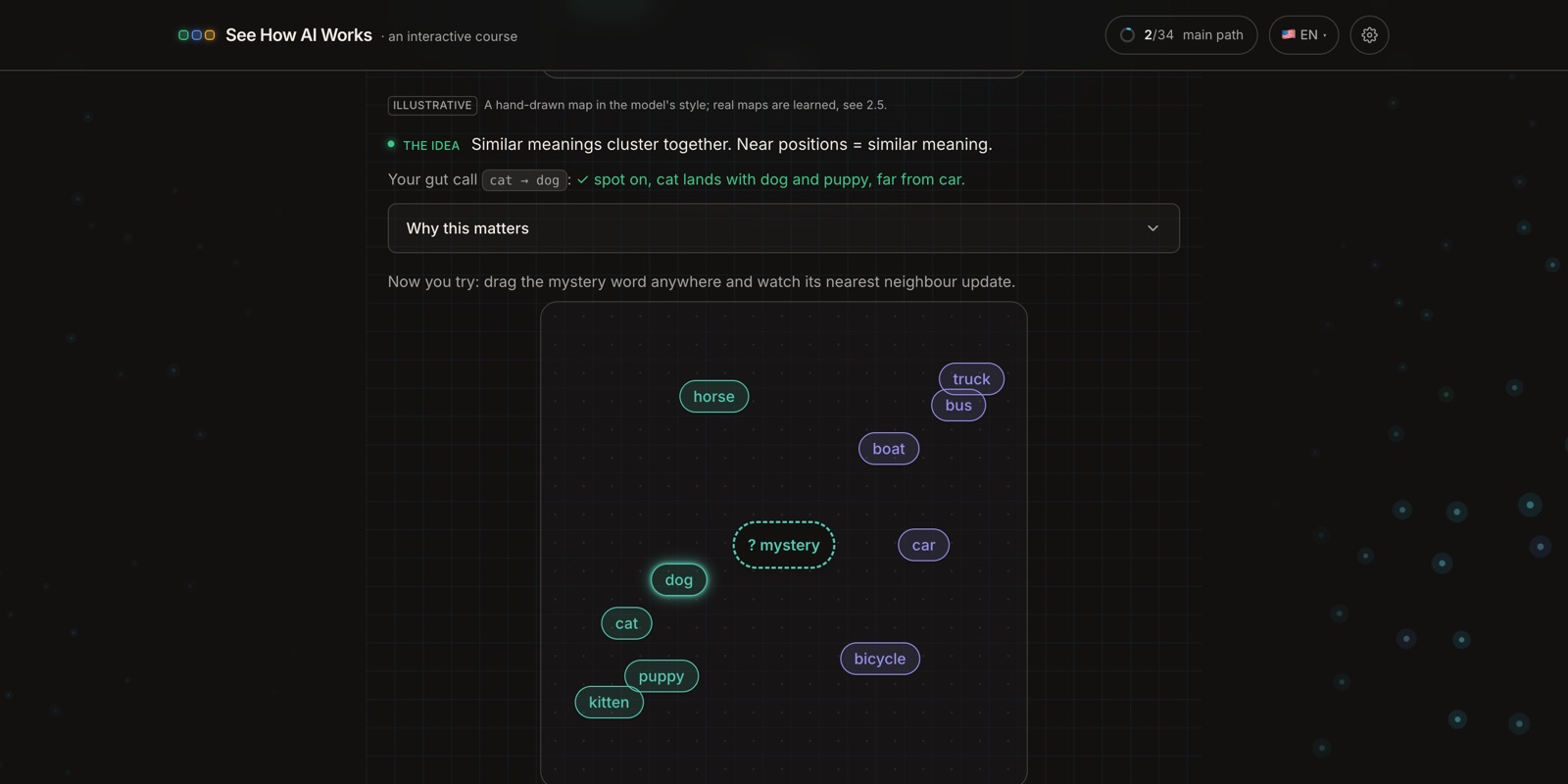
For any of this to be arithmetic, words first have to become numbers. Each word gets turned into a vector: a position in a large space of meaning. The whole point of that space is that position carries meaning. Words that mean similar things sit close together, so "cat" lands near "dog" and "puppy" and far from "car", and distance becomes a measure of how related two things are.
In the course you drop a word onto a scrambled map and watch it sort itself: animals gather in one corner, vehicles in another. Hold onto this one. "Closeness means similarity" is the same trick that powers the next two ideas.
4. Attention: each word looks at the others
A word's meaning depends on the words around it. "Bank" means something different next to "river" than next to "loan". Attention is the mechanism that handles that: every word gets to look at the others in the sentence and pull in the ones that matter, scored with the same closeness measure from before. Each word walks away with a meaning bent by its context.
This is the idea that unlocked modern language models. The lesson shows it as a grid of weights with a focus slider, so you can watch one word put most of its attention on the word it depends on, then sharpen or blur that focus and see the shares shift.
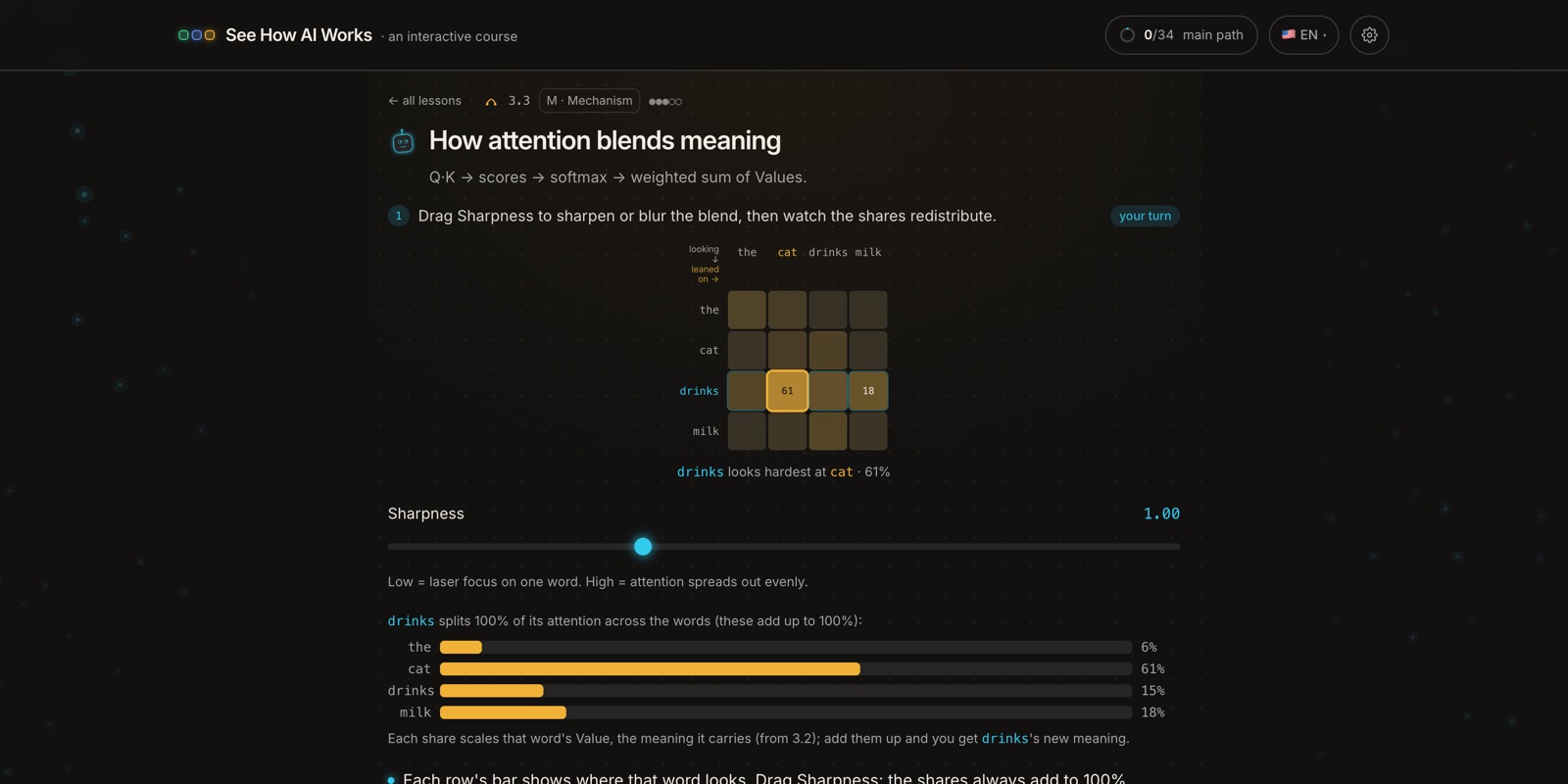
5. A transformer is that block, stacked
"Transformer", the T in GPT, sounds exotic, but it's mostly the attention you just met, packaged into a repeatable unit. One block runs attention, then a small per-word processing step, with a couple of stabilizers wrapped around them so training stays sane.
A single block nudges the words a little. The real move is stacking dozens of them, so each layer refines what the last one produced, and that depth is where the sophistication lives. The course assembles the block part by part, then shows it stacked and feeding back into the next-word prediction from idea #1.
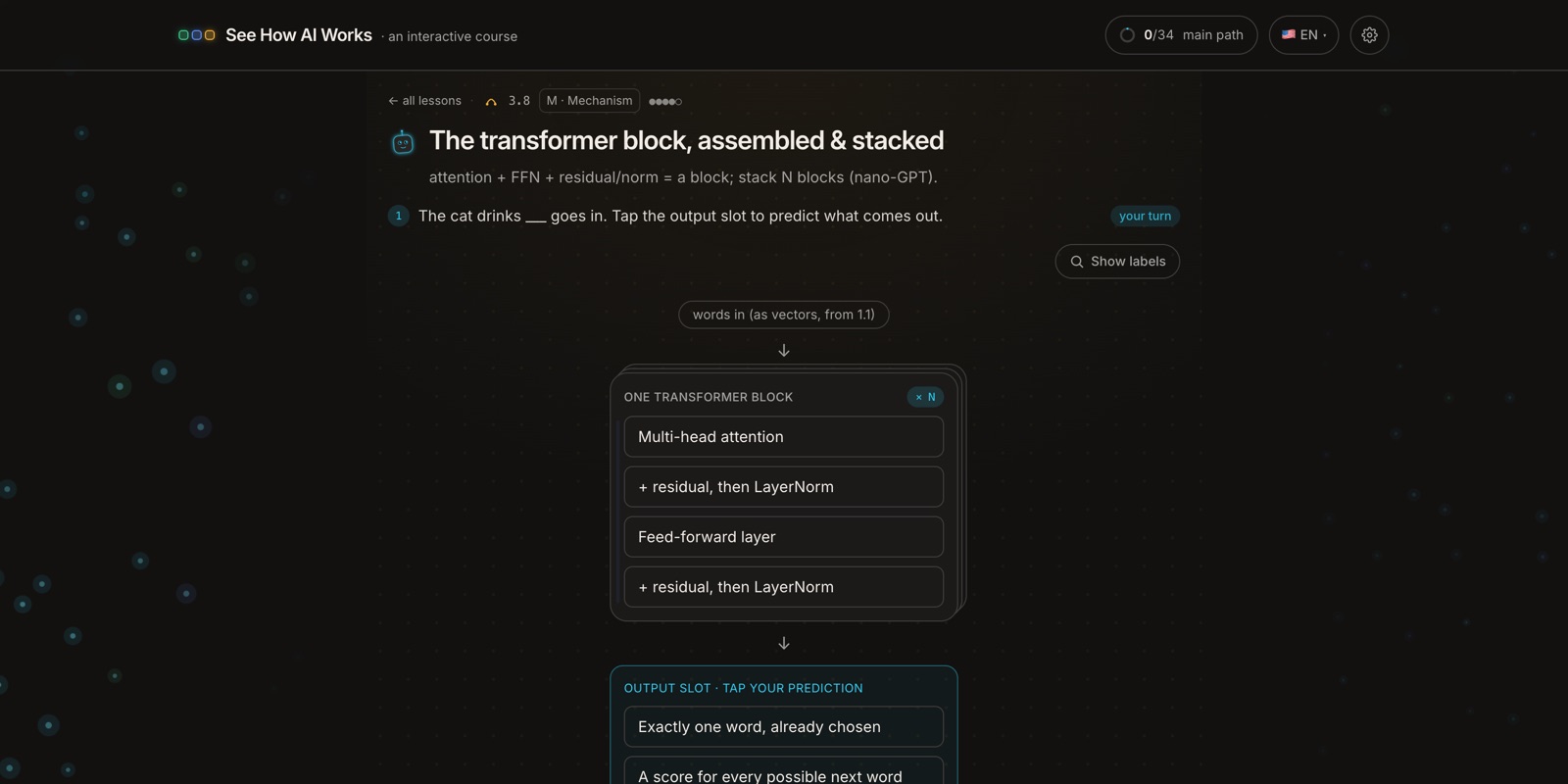
6. RAG: giving a frozen model your own knowledge
Because the model is frozen, it knows nothing about your company's documents or anything that happened after training. RAG (retrieval-augmented generation) is the standard workaround, and it reuses the closeness idea directly. You take the question, search your own text for the chunks closest in meaning, and paste those into the prompt before the model answers.
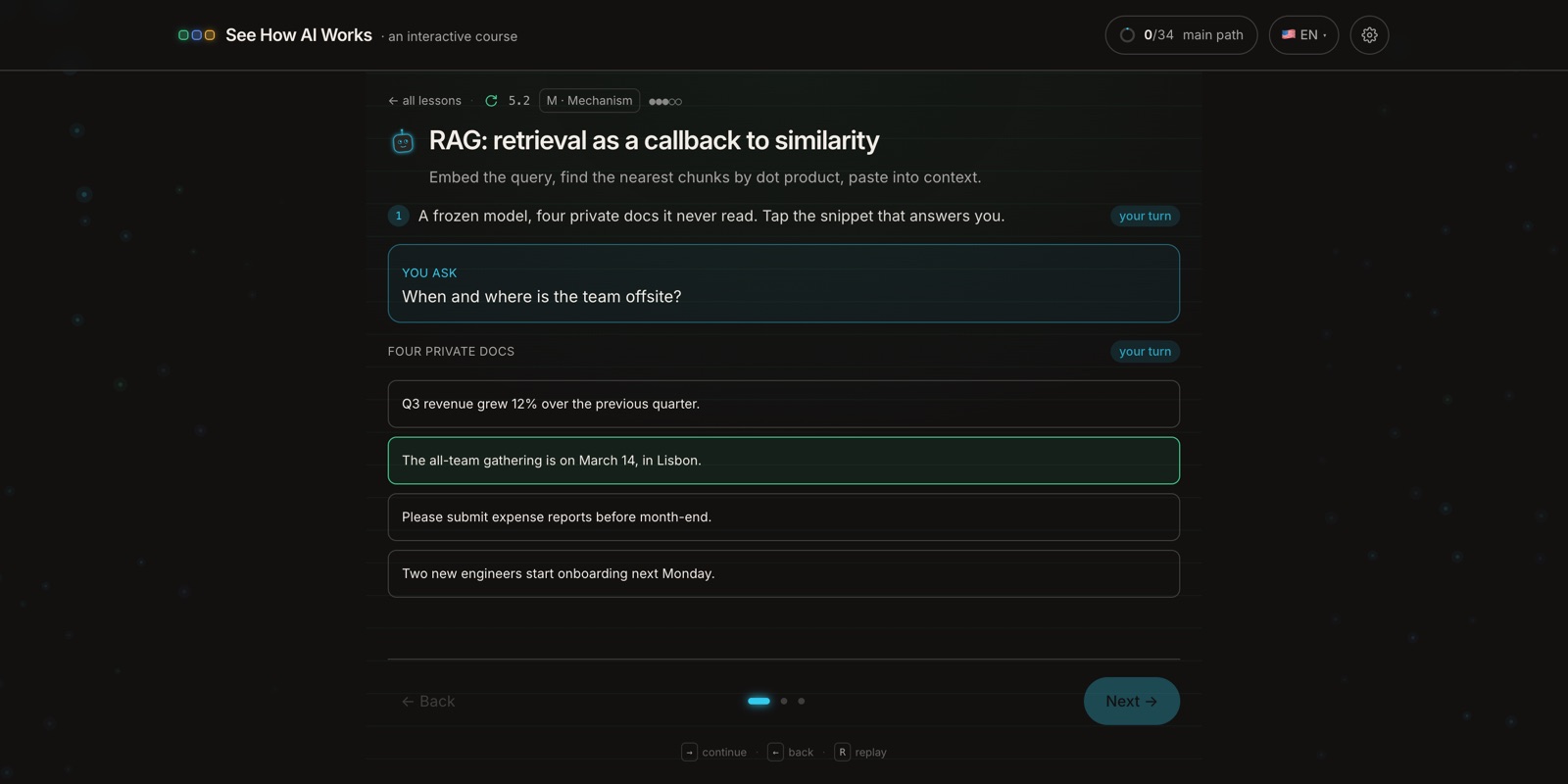
Nothing gets retrained. The model is just handed the right passage to read. Almost every "chat with your documents" feature works this way. In the lesson you ask a question, and out of four private notes the one that actually answers it lights up and gets pulled into context.
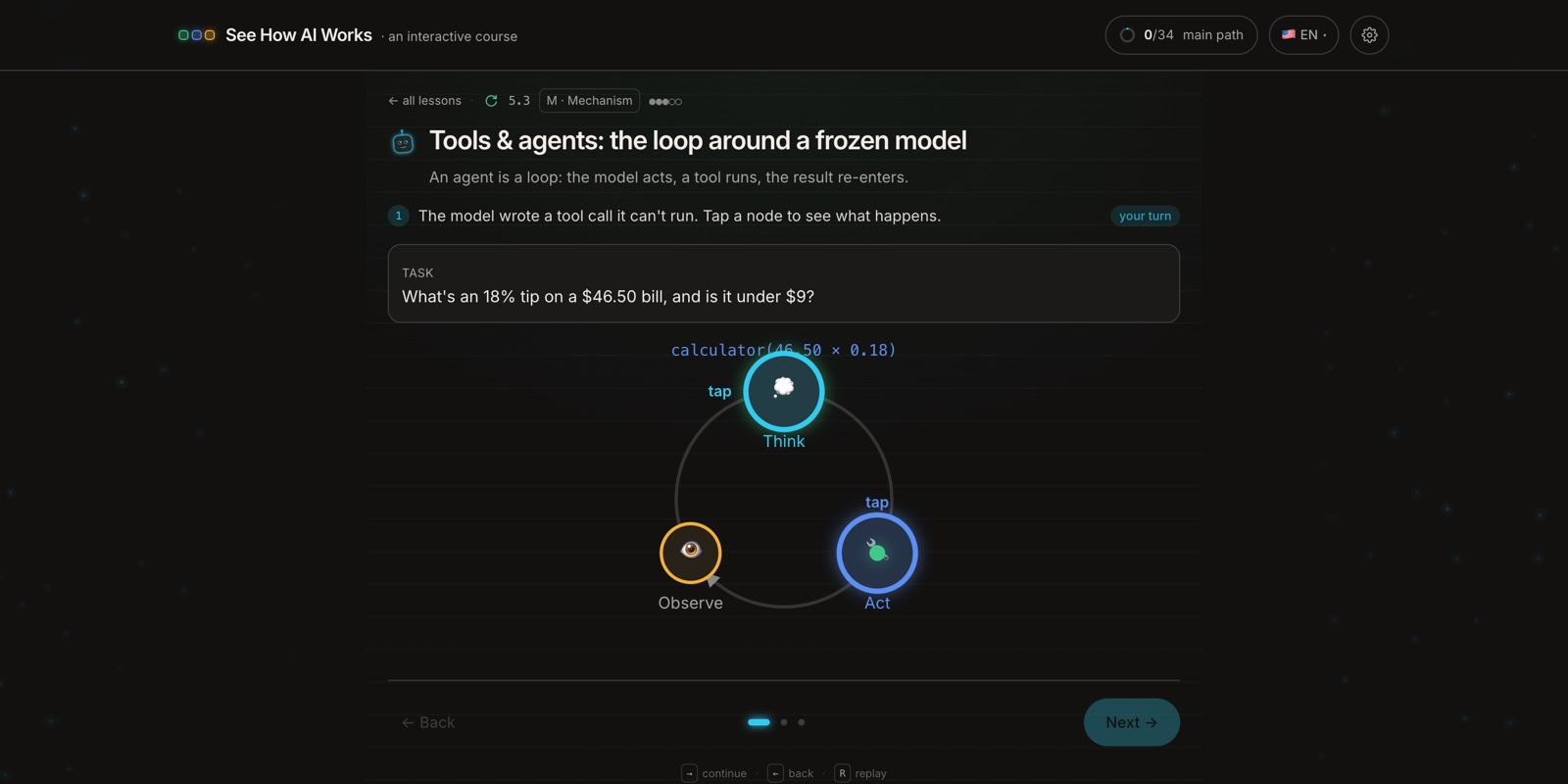
7. Agents: wrap the model in a loop so it can act
A model on its own can only produce text. It can't search, run code, or change anything in the world. An agent is the loop you put around it: the model proposes an action (call this tool with these inputs), the app actually runs it, the result gets fed back in, and the model decides the next step, over and over until the task is done.
The important part is that an agent isn't a cleverer model. It's the same frozen model with a loop and a few tools attached. That's the machinery behind the current wave of AI that books things, edits files, or writes code. The course draws it as a think → act → observe cycle: the model writes a tool call it can't run itself, and the loop runs it and hands back the result.
The whole story
Those seven ideas fit together into one picture: a model that only predicts the next word, trained on the internet and then frozen, working over words-as-vectors, using attention to read context, stacked into a transformer, and extended with retrieval and tools so it can reach fresh knowledge and act. That is most of how today's systems work.
The full course goes further (tokens, scaling, why models hallucinate, how they're evaluated, the hardware underneath), and every lesson is built the same way: a problem you can feel, then the mechanism that solves it, always something you operate rather than read.
It's in early launch, so it's free for the first 100 people who claim it, for life, with a single sign-in and no card. After that it's a one-time purchase, no subscription, and updates are included as the field moves. You can start free, no account needed, at seehowaiworks.com.